



If you’ve built with MCP servers, you’ve felt it. The tool that works in the demo but breaks in production. The integration with no description, no error handling, and parameter schemas that leave your agent guessing. You pick servers based on GitHub stars and vibes, and hope for the best.
That’s not good enough anymore. Agents in production need tools that are actually reliable. Now there’s a way to measure that.
ToolBench is a new benchmark that grades every MCP server in its index across the dimensions that determine whether a tool actually works in production. As of today, 41,902 servers are indexed, 218,422 tools analyzed, and only 0.5% earned an A or above. 167,333 tools received an F.
What does ToolBench measure?
This first version scores servers across four dimensions: definition quality, protocol compliance, security, and supportability. The weight of each depends on server type.
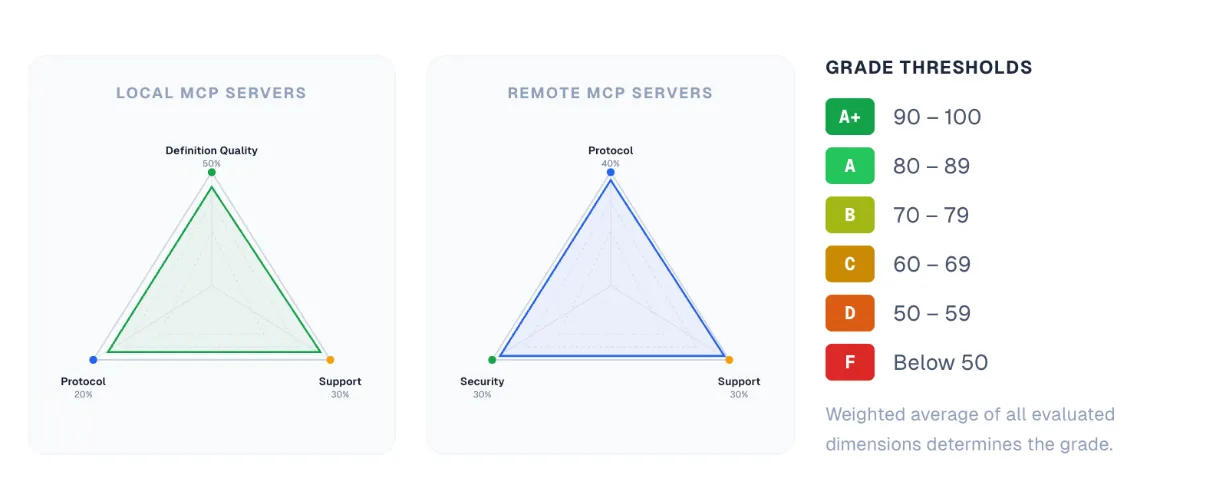
Local servers (GitHub-hosted, source available) are evaluated heavily on definition quality (50%), which scores individual tools on naming clarity, description completeness, and parameter schema rigor. Remote servers shift weight toward protocol compliance (40%), with security and supportability splitting the rest. Scores roll up to a letter grade from F to A+. More dimensions are coming, including ones we’re building out with partners across the MCP ecosystem.
What are the most common quality issues across MCP servers?
Missing descriptions top the list at 6,568 occurrences. When a tool has no description, agents have to guess what it does, when to use it, and what it returns. That guessing shows up as hallucinations, wrong tool selection, and wasted calls.
No error handling guidance comes in second at nearly 1,899 occurrences, which means agents hit failures with no guidance on how to recover. From there, the issues compound:
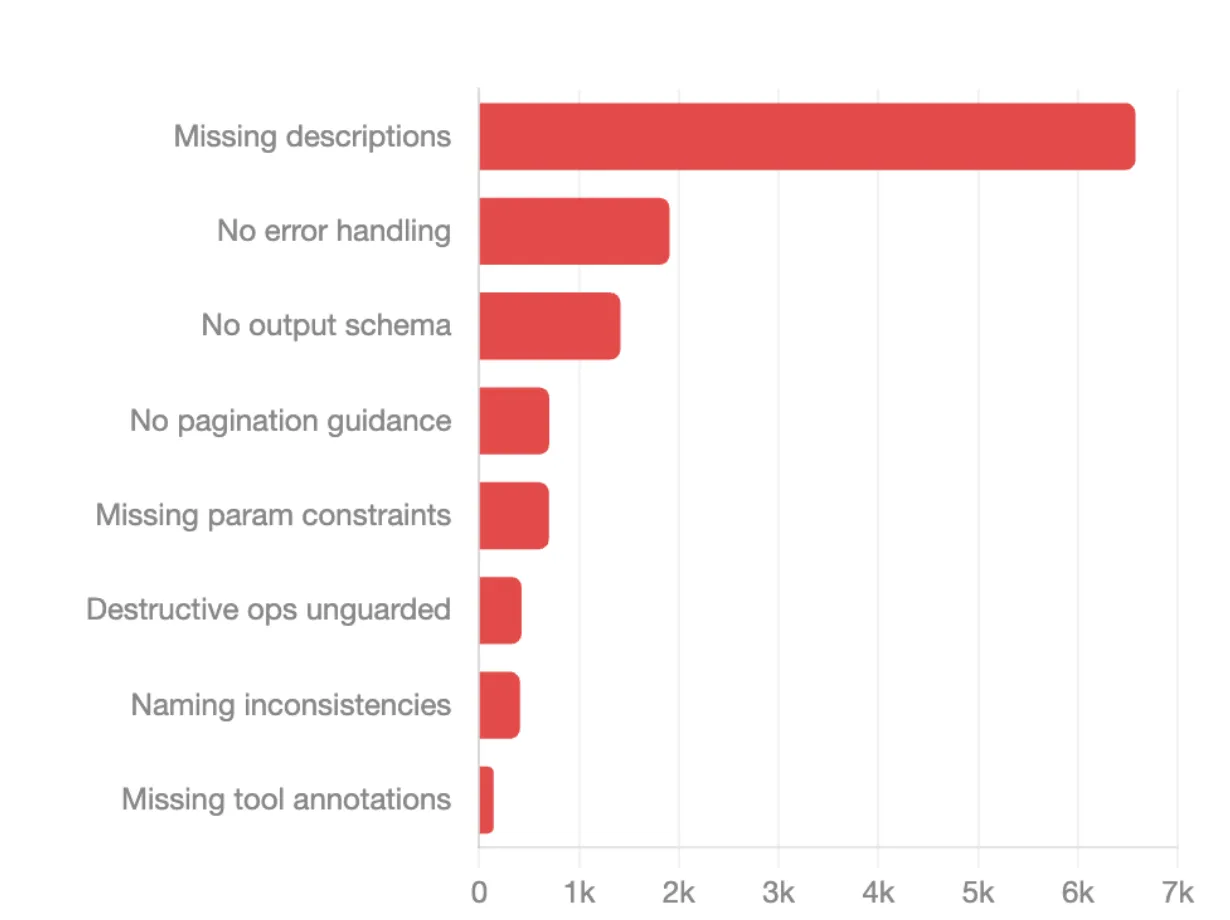
None of these are hard to fix. They’re design discipline issues that get expensive fast once agents are running unsupervised in production.
Where does the scoring criteria come from?
Each dimension is grounded in what actually matters in production.
Definition quality draws on Arcade’s 54 Agentic Tool Patterns, distilled from real deployments with enterprise customers.
Protocol compliance draws on MCP Debugger, Nate Barbettini’s tool that tests your server the way a real MCP client would. He’s spent the past year deep in the hardest parts of MCP and built the debugger because he got tired of finding the same subtle failures by hand.
Security is evaluated against the OAuth 2.1 spec and related RFCs.
Supportability is based on the signals that actually predict whether a project will still be maintained six months from now: activity, ownership, community, documentation.
The full methodology is public on the site.
How do I use it?
If you’re choosing integrations, filter by grade, integration type, or industry before you commit. If you’re building and publishing MCP servers, the criteria are transparent and the gap between an F and an A is almost always a matter of taking tool design seriously. Use it to audit your own servers before your users do.
The ecosystem is still early. ToolBench is a forcing function to raise the floor, and a shared standard the community can build toward. Better tools mean better agents.



