OpenAI just announced GPT 5.6. Well, three versions of GPT 5.6 actually: Sol, Terra, and Luna, plus a new ultra mode that runs multiple agents at once. The flagship is setting coding records, and OpenAI says it spent more than 700,000 A100-equivalent GPU hours trying to (unsuccessfully) jailbreak the thing.
Those are the facts about the announcement, which are certainly impressive but the rollout is the real story, and it says more about where ChatGPT is going than any benchmark does.
The names finally make sense

Let’s start with the names, because they matter more than you might think. GPT 5.6 is the generation. Sol, Terra, and Luna are the capability tiers. Sol is the flagship. Terra is the balanced everyday model, with performance OpenAI compares to GPT 5.5 at half the cost. Luna is the small, fast, token-efficient one.
OpenAI will surely get roasted for changing the naming scheme again, but this one works. The generation tells you how new the model is (5.6), and the name tells you where it sits in the lineup (Sol). You no longer have to remember whether Mini, Turbo, or Pro is supposed to be the smart one. Sol is big, Terra is the middle, Luna is fast.
Easy to follow in my humble opinion…at least until there are 14 variants of each.
The manager is the upgrade, not the workers
The biggest new feature we get with 5.6 is the brand spanking new reasoning controls. A max setting, much like the one from Claude, gives Sol more time to think. An ultra setting goes further, using sub-agents to split up and accelerate complex work.
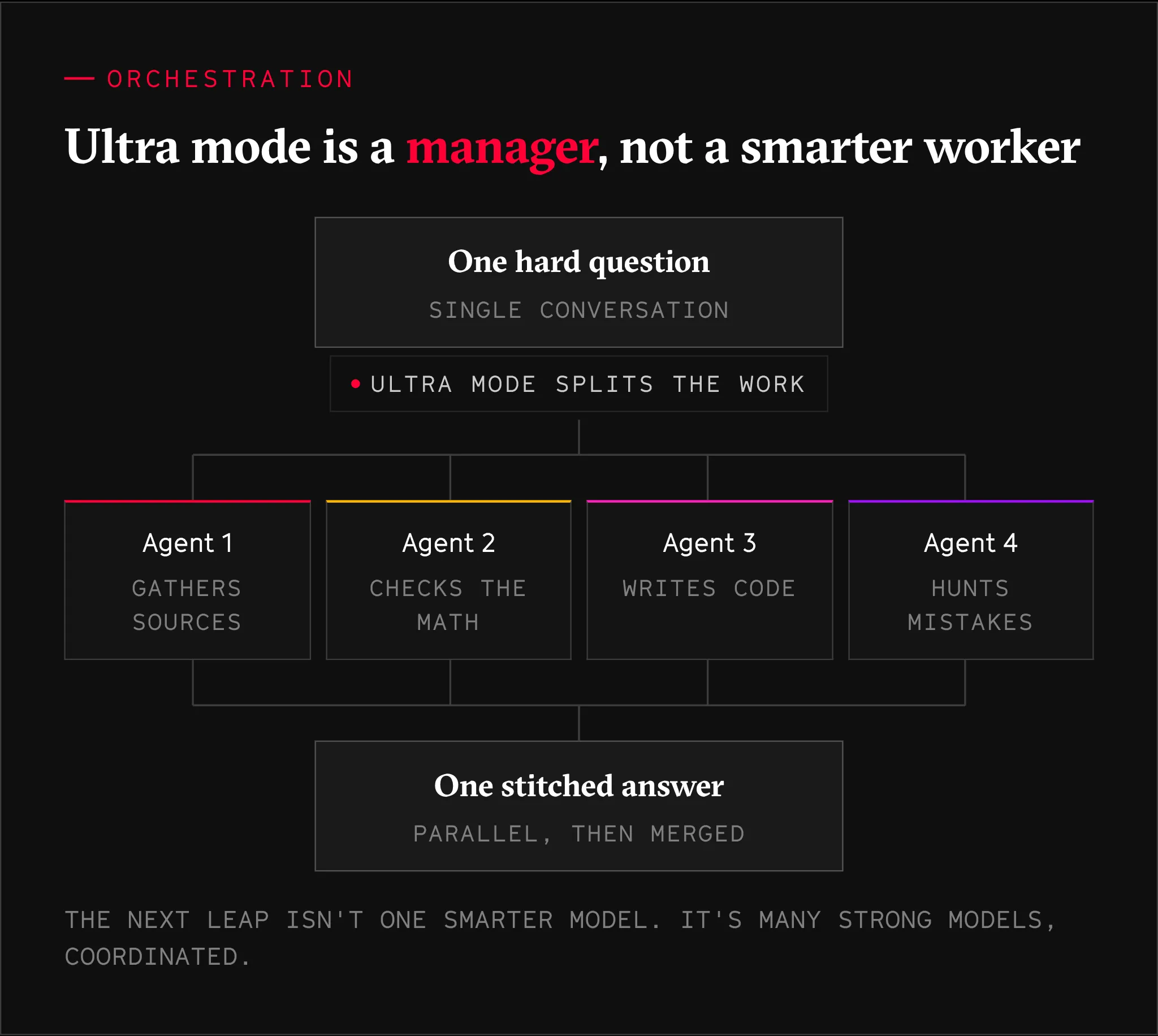
This is a Big Deal™. It represents a huge product shift for ChatGPT. ChatGPT is no longer routing your hard question to a smart model and letting it grind. The system will now break your problem into pieces, hand each piece to an agent, and stitch the results back together when everyone is done working. One agent gathers sources, one checks the math, one writes code, one hunts for mistakes, all in parallel. A team of models behind a single conversation. Pretty close to science fiction if you ask me.
Though the new reasoning toggles are the headline for me, the benchmark results are very impressive as well. On Terminal Bench 2.1, which tests command-line work that needs planning, iteration, and tool use, Sol scored 88.8%. Sol in ultra mode scored 91.9%. For comparison, GPT 5.5 scored 88%. The base model barely moved, but the orchestration led to meaningful gains.
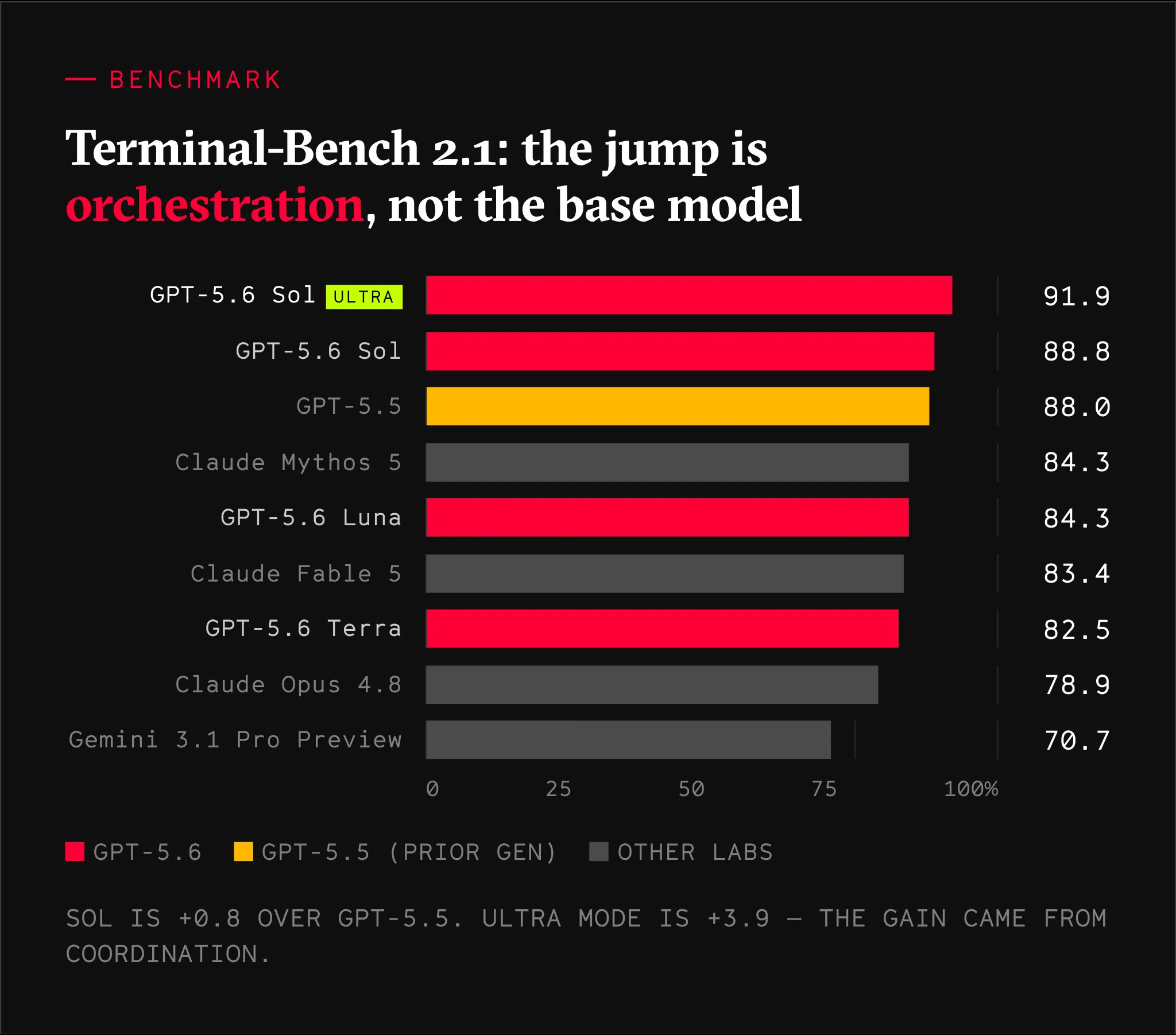
That is the biggest takeaway of this announcement to me. The next leap in capability is not going to come from one smarter model. It is going to come from many strong models coordinating. For years the only thing anyone watched was the model. Now the thing to watch is how a lab wires those models together.
OpenAI is shipping it the Anthropic way
You hear that? That’s the sound of the other shoe dropping.
OpenAI is not putting GPT 5.6 in front of everyone today. The models are entering a limited preview through OpenAI’s API and Codex, for a small set of trusted organizations. OpenAI says it shared the participant list with the U.S. government and previewed the models before launch. It also says it does not want this kind of government process to become the default.
Let me translate that for you.
OpenAI built something powerful enough that it is not comfortable dropping it straight into ChatGPT. The government asked it to slow down. It agreed, for now. And it would like everyone to know it does not want to do this every time.
The tension is now public. OpenAI wants to ship fast. The government wants a look before these models reach hundreds of millions of people. ChatGPT users are caught in the crossfire.
Nervous enough to move the safeguards outside the conversation
OpenAI calls Sol its most capable cyber model yet, able to find vulnerabilities, identify exploitation primitives, and run long-horizon security work faster than anything before it. On its Chromium and Firefox tests, OpenAI says the model did not autonomously build a full working exploit chain, so it stayed under the company’s cyber-critical line. They are also careful to admit that the benchmarks cannot cover every real workflow or tool combination.
Translated again: the model did not cross the red dotted line, but OpenAI is very nervous about what happens when people wire it into real systems.
To best prepare for bad actors (or good actors with skill issues), the safeguards got heavier. The model can now refuse to carry out a prompt. Real-time classifiers read output as it is generated and a bigger reasoning model can pause a response and approve or deny it. Flagged activity can trigger an account-level review across multiple conversations. The controls are no longer scoped to one message. The system now watches behavior over time, the tools in play, and the risk of the whole workload. We saw a softer version of this with Fable 5, which punted security-adjacent questions to another model.
The numbers for builders
For the developers: Sol is $5 per million input tokens and $30 per million output. Terra is half that. Luna is $1 in and $6 out. OpenAI says Sol will run on Cerebras at up to 750 tokens per second starting in July for select customers.
A frontier model at 750 tokens per second is wild. At that speed the system can reason, delegate, call tools, check the results, and answer before you finish reading what you sent. Is that AGI I smell in the oven?
The model reasons. The runtime governs.
Once ChatGPT can spin up sub-agents, use tools, and act across real systems, the interesting question is no longer how smart it is.
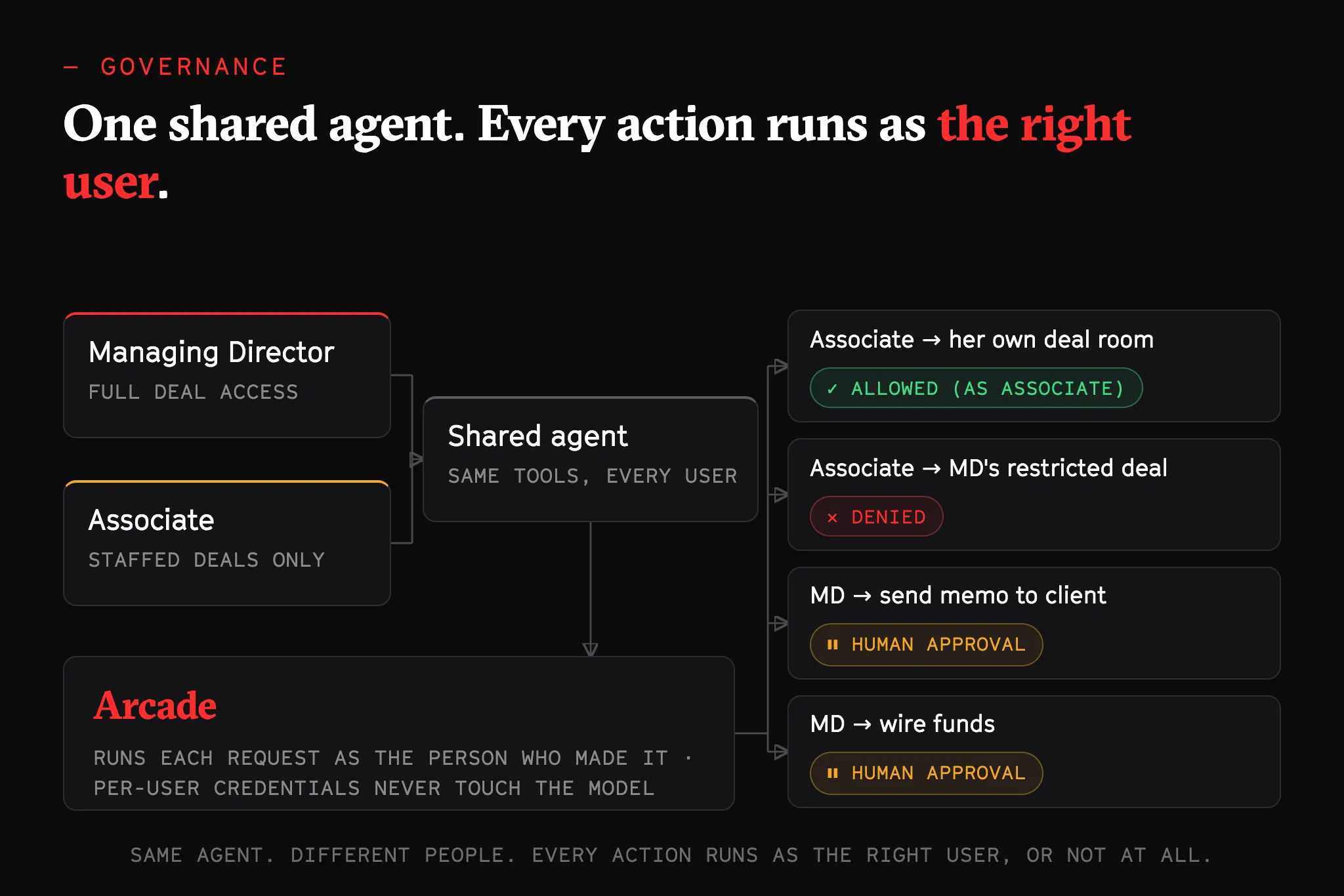
Now picture a whole deal team sharing one agent. An associate asks it to pull the financials for the deal she is staffed on and build the model. A managing director (MD) asks the same agent to send the final memo to the client and open the numbers from a different deal, one the associate was never cleared to touch. Same agent, same tools, two very different levels of access.
So the question is no longer just whether an action should run. It is who it should run as. The moment that shared agent answers the associate with the MD’s reach, it becomes the easiest way in the building to get access nobody granted.
That is the whole problem. As which user is each action running? What can that person actually access? Which actions need a human, and whose approval? How do you enforce policy on every tool call, and prove afterward who did what?
It should also be noted that this is the extremely tame version. We already have evidence that running multiple agents at once is quickly becoming the norm. OpenAI’s own Codex research found that active users grew more than fivefold in the first half of 2026, and that more than 10% of them now run three or more agents at the same time in a typical week. Now remember what ultra mode does: it lets each of those agents spin up its own sub-agents. So one person kicks off three agents, each of those spins up three more, and so on down the tree. A single instruction at the top fans out into dozens of real actions across real systems before anyone looks up. The leverage is about to compound, and the number of actions you have to account for is going to explode right along with it.
Reasoning and authority are different jobs. A brilliant new intern doesn’t get the keys to the castle on day one, and a brilliant model should not either. The model decides what to do. Something outside the model has to decide what it is allowed to do.
The good news for you dear reader is that you do not need a new trust model for this. The identities, groups, scopes, and approvals your team already runs are the same controls that should govern what an agent does on your behalf, whether one person runs a swarm of sub-agents or a whole team shares one agent. That is the layer we build at Arcade.dev. We helped write the Model Context Protocol (MCP) authorization spec that a lot of this runs on. On every tool call, Arcade checks the action against your policy and the real permissions of the person it is acting for, keeps each user’s credentials away from the model, asks for human approval when the request is sensitive, and writes an audit record of who did what.
GPT 5.6 is a preview of the next ChatGPT, and the next ChatGPT is a workforce. OpenAI builds the workforce. You still have to authorize the work. The model reasons. The runtime governs. If you are putting agents into production, come see what we are building.